目录
1、背景
最近在做面试复盘,但录音的内容太长,听音频的方式又太低效
需要把录音转成文字,阅读的方式会快很多
尝试了几种白嫖的方案后,效果转换都不理想,并且限制录音时长,撑死就是几分钟,完全不够用
于是,不得不斥巨资19.8元,在传说国内语音最强的某飞官方购买录音转文字服务

2、效果对比
录音内容主要是介绍我做过有代表性的项目,左边是OpenAI开源Whisper,右边是某飞付费
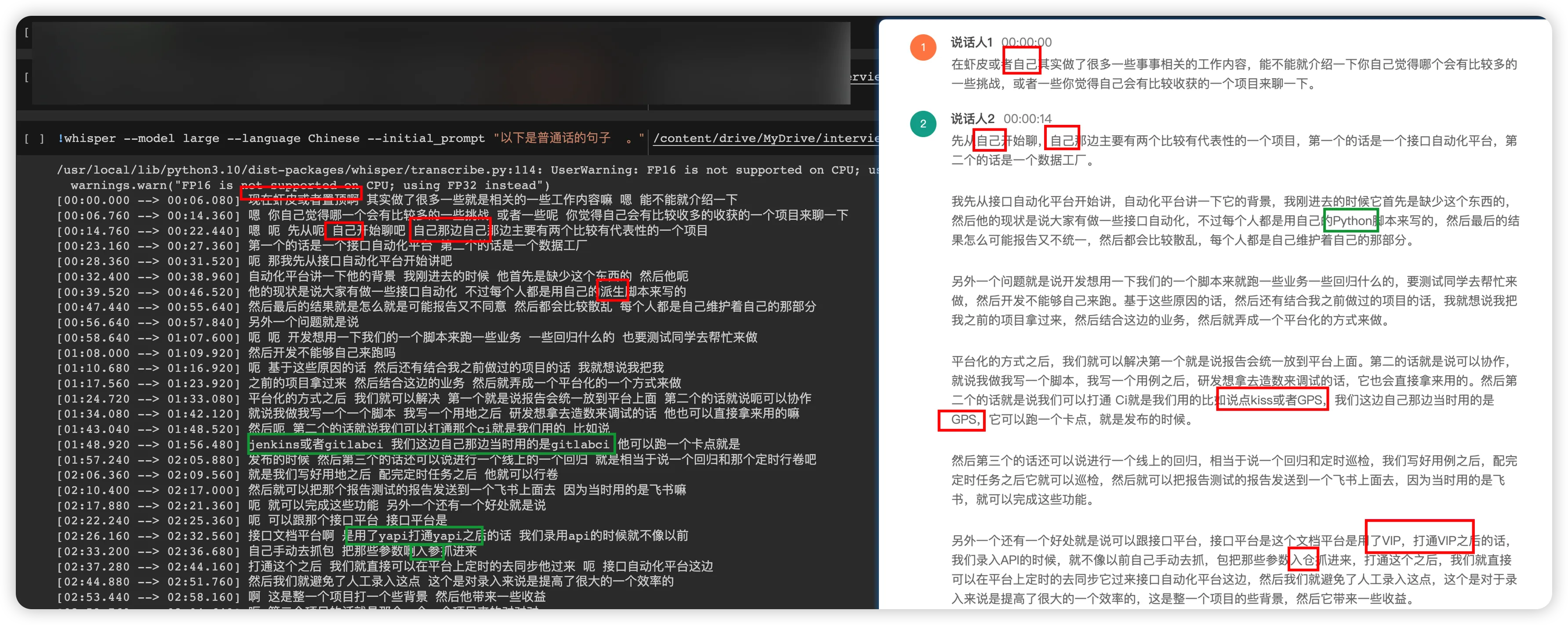
截图中,红色圈表示错误的,绿色表示正确的 最终结果是whisper 4 vs 1 完胜某飞
| 词语 | whisper | 某飞 |
|---|---|---|
| 致景 | 错误(自己) | 错误(自己) |
| Jenkins | 正确 | 错误(说点kiss) |
| GitlabCI | 正确 | 错误(GPS) |
| yapi | 正确 | 错误(VIP) |
| 入参 | 正确 | 错误(入仓) |
| python | 错误(派生) | 正确 |
3、如何使用whisper
3.1 colab
colab这是我唯一找到支持安装whisper环境,并且免费提供GPU的AI平台!
Kaggle似乎也行,但用起来很不稳定。
如果你有更多的免费GPU平台,非常欢迎你留言交流
在colab上使用whisper超级简单
3.1.1 注册colab
在https://colab.research.google.com/这里注册即可
3.1.2 安装whisper环境
新建笔记本
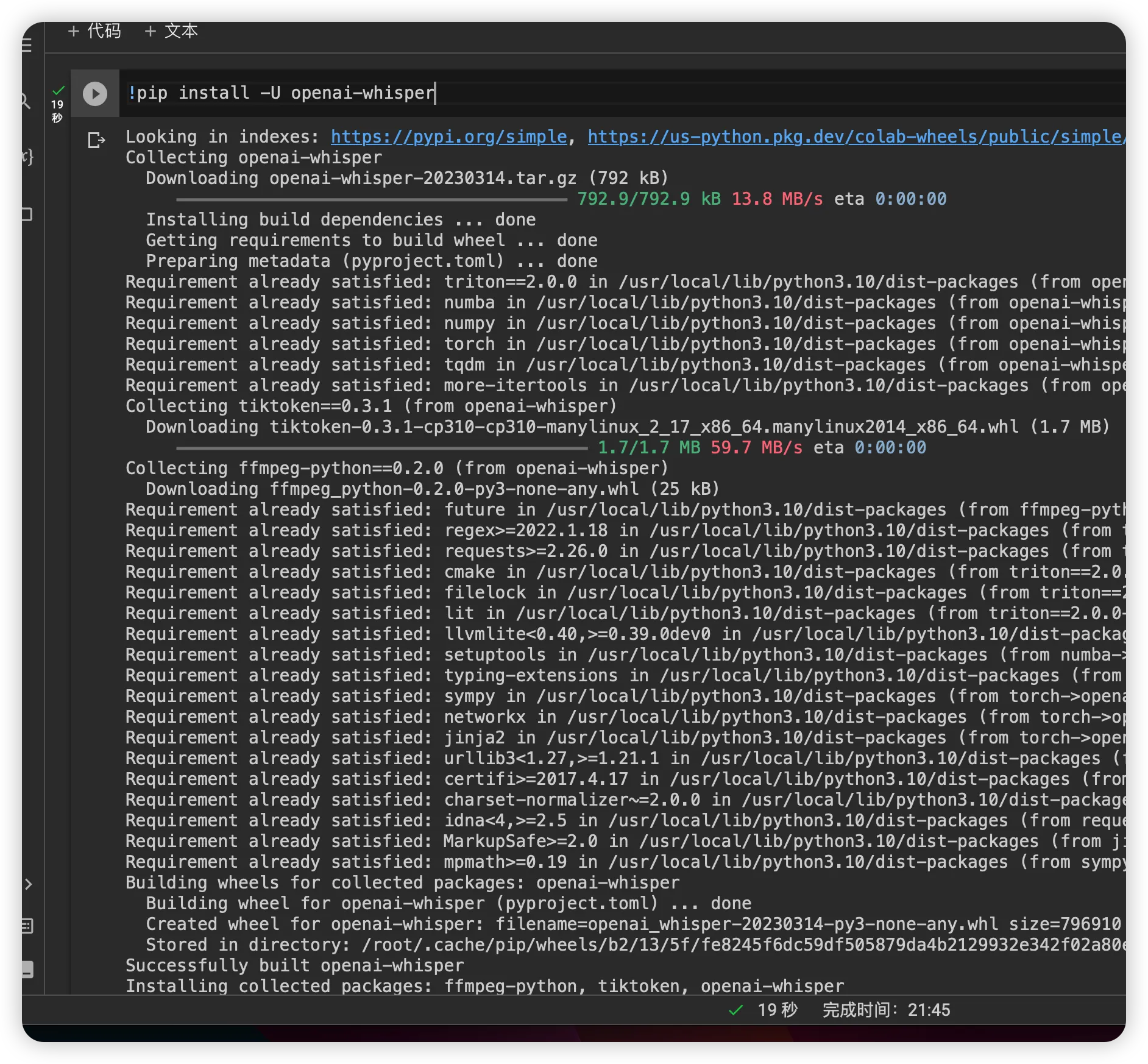
安装whisper依赖
!pip install -U openai-whisper
3.1.3 使用whisper
上传你的录音
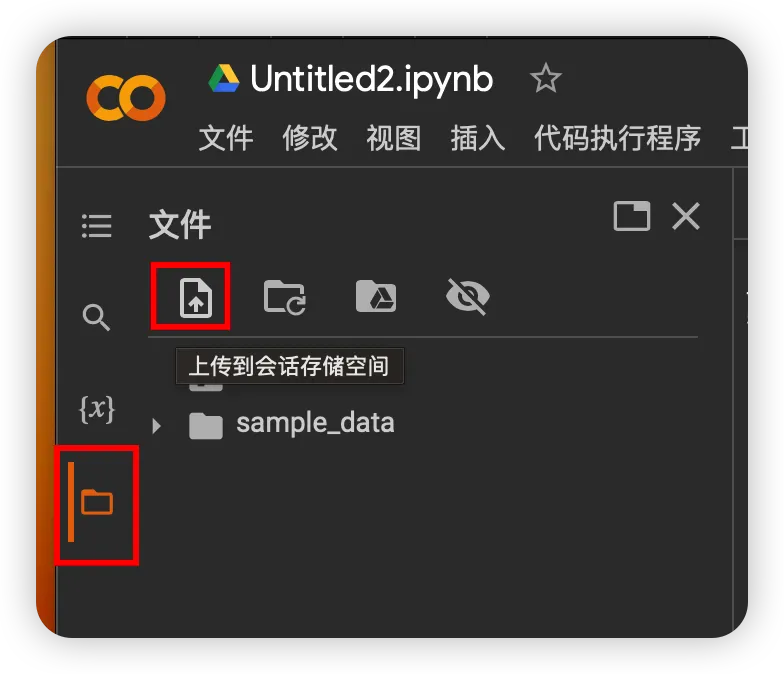
复制文件路径并执行命令
!whisper --model large --language Chinese --initial_prompt "以下是普通话的句子 。" 你的文件路径
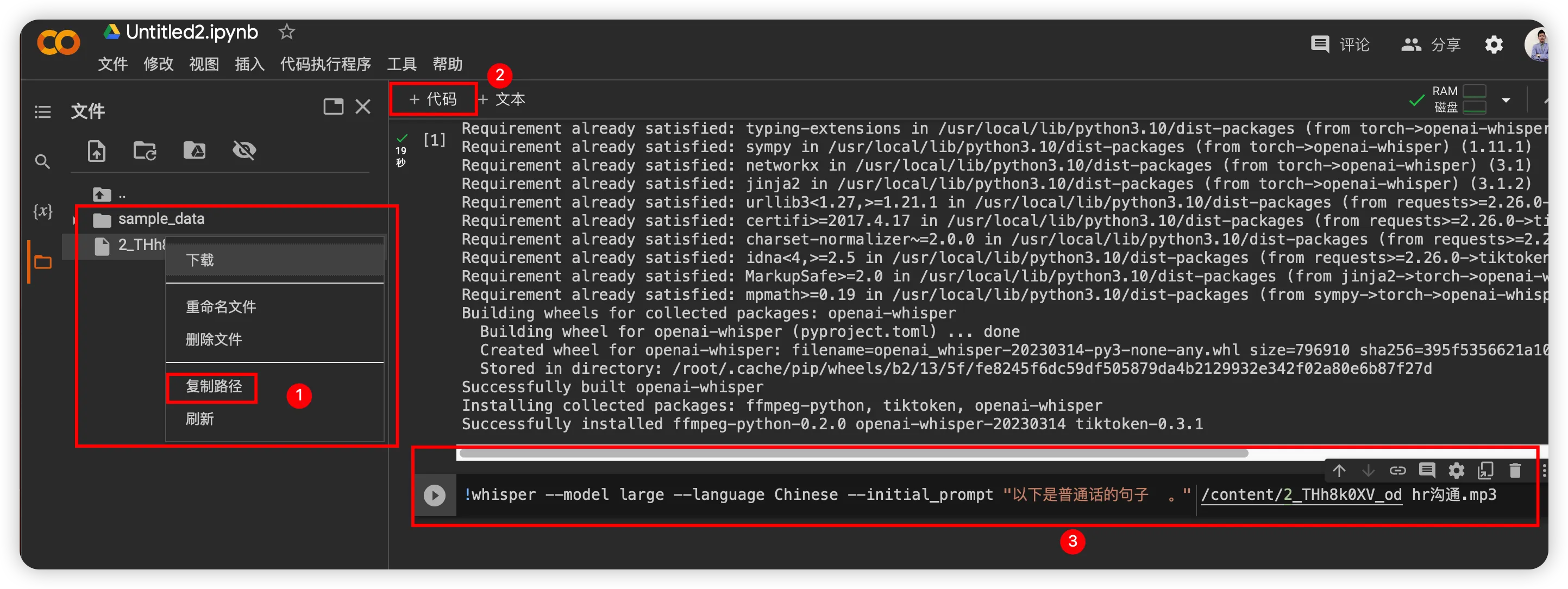
模型很大,你需要等(忍)一下
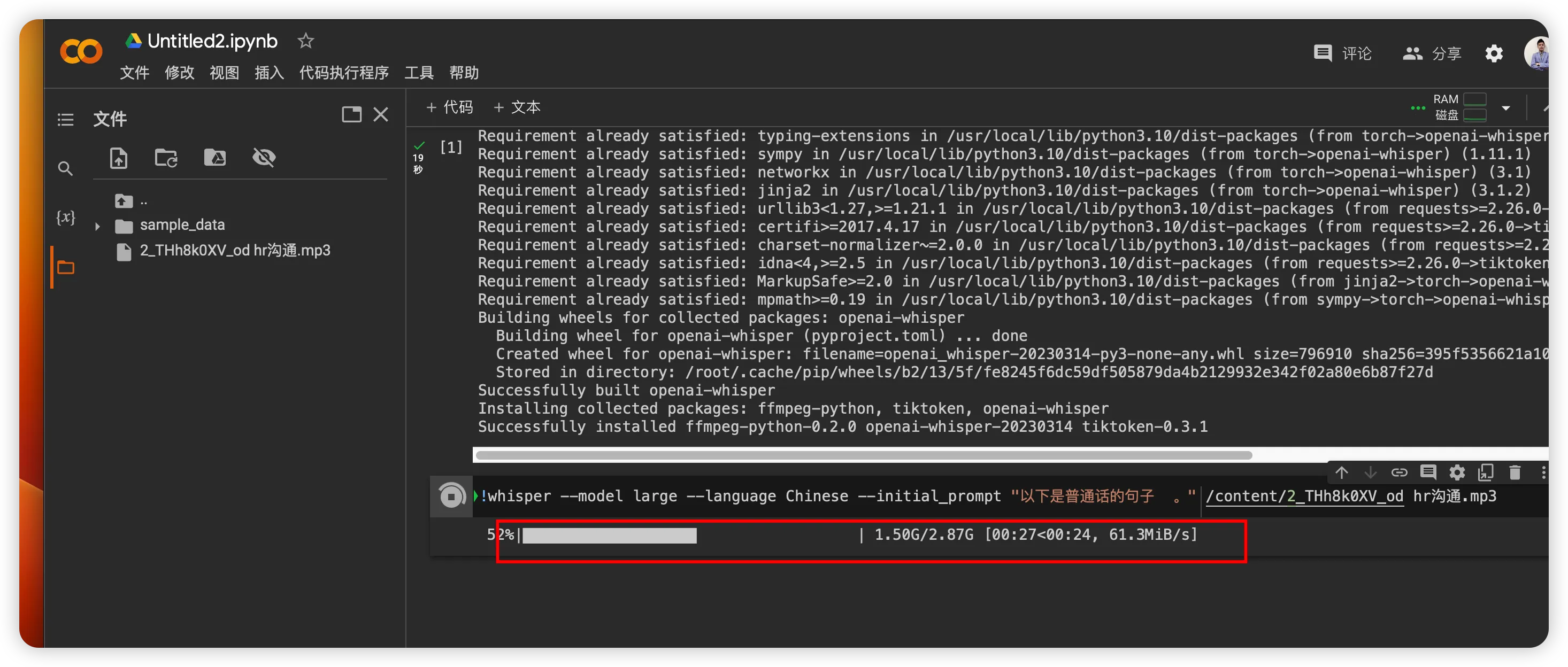 默认会使用CPU运行时,效率比较低
默认会使用CPU运行时,效率比较低
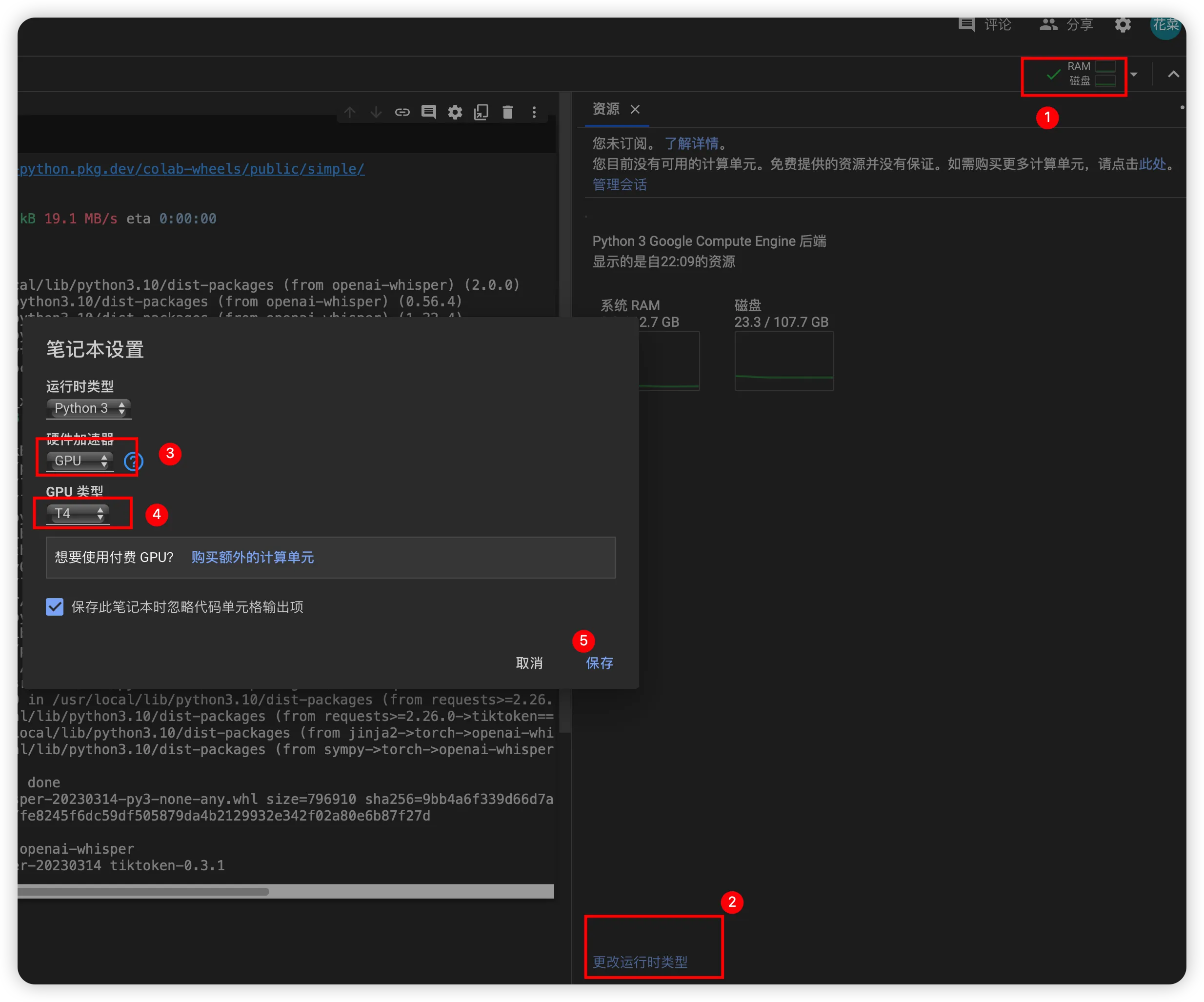
切换GPU运行时,GPU会比CPU快很多
但都是免费资源,无法保证全力输出
GPU免费只有12小时,省着点用
用完后,记得点击右上角连接断开
最后看看一小段跟od hr对话的效果

3.2 本地运行
如果需要在本地运行的话,需要安装ffmpeg命令行
python版本最好是3.9
其他的跟上面没区别
友情提示,如果你没有GPU,最好不要在本地运行;CPU即使拉满,输出的速度也是远不及GPU
因为我本地没有GPU,所以不了解本地应该怎么配置GPU
本文作者:花菜
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!